Windows powershellがchcpでUTF-8対応という話でしたが、どうもおかしいのです。仕様書も見つけられないし振る舞いもあやしい。コマンドプロンプトの方が理解できる振る舞いをします。WindowsはウェブブラウザがOSの一部だと主張しながら、まともなエディタを作りませんでした。また、DOSの上にWindowsを乗せているのではなく、GUIでコントロールする一体のOSだと言ってコマンドプロンプトを旧態のままにしておいて、突然powershellなるものを出してきました。2006年のWindows vistaからJIS X 0213対応をしましたが、他国版と共通にUnicodeを使うようにしたということです。旧JISに対応したShift_JIS+αだったMS932という文字コードは+αの部分が邪魔をしてUnicodeに移行できないのでそのまま残し、別にUTF-8での入出力を設けてJIS X 0213が必要ならばそれを使うことにしたのです。コマンドプロンプトはMS932のままに残されました。その歴史の上に出てきたpowershellは、当然JIS X 0213に対応していると期待をしたのですが、やっぱりだめだったということでした。それに比べるとLinuxの仮想端末は立派になっていると思います。2019年10月下旬のお話です。
普段はLinux上でプログラムを書いていますが、事情があってWindows10でコンパイルと実行ができることを確認する作業をしました。ところがうまくいきません。問題はサロゲートペアでした。
Windowsでの確認とは、html文書に書いたプログラムをコピー&ペーストでエディタに取り込んで保存し、powershell上でJDKでのコンパイルと実行です。自然とShift_JISでの保存になり、そのままjavacコマンドで処理され、javaコマンドで実行するということで、いままで問題が起こったことはありません。
今回のプログラムは、サロゲートペアを含む文字列を一文字ずつ取り出して処理をするものでした。
そうです。WindowsのShift_JISではサロゲートペアを使うような文字を処理できないのです。10年以上Linuxメインでしたので、すっかり忘れていました。原因はJavaではなくエディタです。
正しくUTF-8で保存できるエディタを使って、コンパイラにUTF-8を指示して、CUIへの文字としての表示は諦める。というのが妥当なところでしたが、今回の事件で Windows powershell にchcpというコマンドがあることを知りました。ひょっとして文字表示もできるかもと思ったのが今回のハマりどころです。
いかにWindowsでもブラウザはUTF-8で書かれたページも正しく表示されますから、次はエディタがUTF-8で正しく保存できるかということです。
私が昔からWindowsで使ってきたエディタはUTF-8で保存できるのですが、残念ながら内部の処理がShift_JISで、それに含まれない文字は??としてしまいます。だから使えない。結局Linuxで使っているgeditのWinndows版をインストールして使いました。LinuxからWindowsに移植されるソフトは増えてます。
Javaは置かれた環境でのデフォルトの文字コードを感知してコンパイルします。Shift_JIS環境でソースコードがUTF-8の時には次のようにすれば良いことになっています。
javac -encoding UTF-8 hogehoge.java
作成されるクラスファイルはソースの文字コードによらず同じものができます。
実行は
javac hogehoge.java
で、出力が環境に合わせて自動的にShift_JISになるので、普通は問題なく表示されます。
今回はサロゲートペアの文字が含まれるので、この最後の表示部分が問題になるのです。
ちなみに、原因がサロゲートペアのように書いていますが、正確にはちょっと違います。
| 分類 | JIS X 0213(IBM拡張の一部を含まない) | |||
|---|---|---|---|---|
| MS932 | X0213で追加された文字 | |||
| X0208の文字 | IBM拡張 | BMP内 | サロゲート ペアが必要 |
|
| 例 | 東西南北 | 杦樰鉧銧 | 囨艹辶鰙 | 𠀋𡈽𩸽𡗗 |
Shift_JISは本来は JIS X 0208 の部分のみを含みますが、一般的にはMS932と同等に受け取られます。
さらに JIS X 0213 を完全に網羅するShift_JISX0213もあり、面倒です。
IBM拡張の一部は JIS X 0213 には含まれず、また含まれるものも登録位置が変更になっていて、これがWindowsがShift_JISX0213に移行できなかった理由と思います。
こういうことなので、サロゲートペアでなくてもMS932で表現できない文字がたくさんあります。むしろサロゲートペアを必要とする文字は少数です。
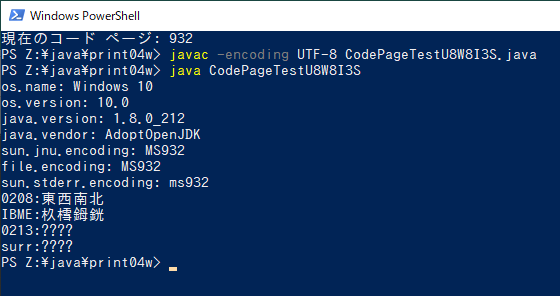
まず、Javaプログラムで表示してみる。コンパイルのやり方と、サロレートペアに限らず、JISX0213で追加された文字が表示できないことが確認できる。os.nameなどは実行環境を残すために加えている。
文字に起こしておきます。
PS Z:\java\print04w> javac -encoding UTF-8 CodePageTestU8W8I3S.java PS Z:\java\print04w> java CodePageTestU8W8I3S os.name: Windows 10 os.version: 10.0 java.version: 1.8.0_212 java.vendor: AdoptOpenJDK sun.jnu.encoding: MS932 file.encoding: MS932 sun.stderr.encoding: ms932 0208:東西南北 IBME:杦樰鉧銧 0213:???? surr:????
プログラムの内容は
import java.util.Properties;
public class CodePageTestU8W8I3S {
public static void main( String[] args ) {
System.out.println( "os.name: "+System.getProperty("os.name"));
System.out.println( "os.version: "+System.getProperty("os.version"));
System.out.println( "java.version: "+System.getProperty("java.version"));
System.out.println( "java.vendor: "+System.getProperty("java.vendor"));
System.out.println( "sun.jnu.encoding: "+System.getProperty("sun.jnu.encoding"));
System.out.println( "file.encoding: "+System.getProperty("file.encoding"));
System.out.println( "sun.stderr.encoding: "+System.getProperty("sun.stderr.encoding"));
System.out.println( "0208:東西南北" );
System.out.println( "IBME:杦樰鉧銧" );
System.out.println( "0213:囨艹辶鰙" );
System.out.println( "surr:𠀋𡈽𩸽𡗗" );
}
}
Windows powershellのデフォルトの文字コードはMS932です。
Javaの前にtypeコマンドでの表示で確認します。そのために2つのテキストファイルを用意します。
ms932.txt(MS932で保存)。これはMS932で表現できる文字だけです。
aaaa MS-932-cat|type 0208:東西南北 IBME:杦樰鉧銧
utf8.txt(UTF-8で保存)
aaaa UTF-8-cat|type 0208:東西南北 IBME:杦樰鉧銧 0213:囨艹辶鰙 surr:𠀋𡈽𩸽𡗗
chcpは多分、change codepage の略で、引数なしだと現在の様子が表示されます。
PS Z:\java\print04w> chcp 現在のコード ページ: 932
MS932は正常
PS Z:\java\print04w> type ms932.txt aaaa MS-932-cat|type 0208:東西南北 IBME:杦樰鉧銧
UTF-8のファイルをMS932として表示するわけで、文字化けします。画面に出たものをそのままコピーして貼り付け、UTF-8で保存したもので全く同じに再現できているかはわかりませんが、雰囲気は似ています。
PS Z:\java\print04w> type utf8.txt aaaa UTF-8-cat|type 0208:譚ア隘ソ蜊怜圏 IBME:譚ヲ讓ー驩ァ驫ァ 0213:蝗ィ濶ケ霎カ魏・surr:愚。或クス覧
Javaは内部のUTF-16のデータをMS932に変換して表示するので、この表示とは異なります。
chcp 65001で表示がUTF-8なるという話です。確認します。
PS Z:\java\print04w> chcp 65001 Active code page: 65001
chcp 65001を打つと画面がクリアされるので、上のようには残りません。Active code page: 65001 からのスタートになります。
PS Z:\java\print04w> type ms932.txt aaaa MS-932-cat|type 0208:東西南北 IBME:杦樰鉧銧
おやおや変わりません。
PS Z:\java\print04w> type utf8.txt aaaa UTF-8-cat|type 0208:譚ア隘ソ蜊怜圏 IBME:譚ヲ讓ー驩ァ驫ァ 0213:蝗ィ濶ケ霎カ魏・surr:愚。或クス覧
UTF-8も同様です。身内の出す表示が変わらないというのは奇妙です。
ではJavaを使ってみます。
PS Z:\java\print04w> java CodePageTestU8W8I3S os.name: Windows 10 os.version: 10.0 java.version: 1.8.0_212 java.vendor: AdoptOpenJDK sun.jnu.encoding: MS932 file.encoding: MS932 sun.stderr.encoding: cp65001 0208:k IBME: 0213:???? surr:????
漢字が表示されません。Java側としてはpowershellがUTF-8環境であると理解してUTF-8で出すか、変更が理解されずにMS932のまま出すかのどちらかですが、どちらにしてもこの表示は理解できません。
このために漢字部分の上のシステムプロパティを用意しました。chcpによって「sun.stderr.encoding」が変化したことが見て取れます。stderrというのが気になれます。
デフォルトのエンコーディングが file.encoding プロパティに設定されているという情報があります。上記を見直すと、file.encoding: MS932 となっていますから、変更が理解されずにMS932として出力している可能性を考え、出力をUTF-8にするように指示してみます。
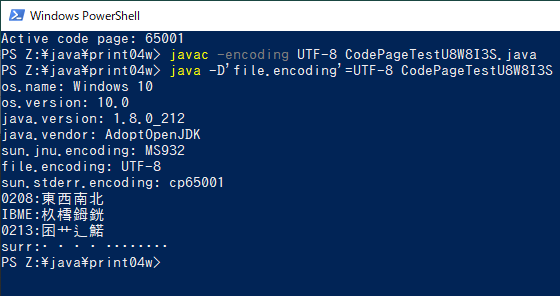
PS Z:\java\print04w> java -Dfile.encoding=UTF-8 CodePageTestSJW813S
出力が一切なくなります。ASCII部分も含めて全部です。オプションの中のドットが悪さをしているようです。
PS Z:\java\print04w> java '-Dfile.encoding=UTF-8' CodePageTestU8W8I3S os.name: Windows 10 os.version: 10.0 java.version: 1.8.0_212 java.vendor: AdoptOpenJDK sun.jnu.encoding: MS932 file.encoding: UTF-8 sun.stderr.encoding: cp65001 0208:東西南北 IBME:杦樰鉧銧 0213:囨艹辶鰙 surr:𠀋𡈽𩸽𡗗
CodePageTestU8W8I3Sの後ろにスベースがたくさん入りos.nameが続けて入ってしまいます。上記は修正しています。
サロゲート部分はコピーしてUTF-8に貼り付けた時点で漢字になります。powershell内では 「surr:. . . . ........」 と表示されています。
javacのオプションは-encodingでjavaは-Dfile...ですが、これはコマンドの-helpで確認できます。
javac -helpでは
-encoding <encoding> ソース・ファイルが使用する文字エンコーディングを指定する
java -helpでは
-D<name>=<value> システム・プロパティを設定する
とあります。システム・プロパティが上記のプログラムにあったfile.encodingやsun.stderr.encodingだというわけです。
ちなみに、コンパイルもUTF-8を指定しなければだめです。このファイルはUTF-8で書かれています。0208の部分とIBMEの部分ではエラーになっていないのがちょっと不思議ではあります。
PS Z:\java\print04w> javac CodePageTestU8W8I3S.java
CodePageTestU8W8I3S.java:23: G[: ́̕AGR[fBOMS932Ƀ}bvł܂
System.out.println( "0213:囨艹辶?" );
^
CodePageTestU8W8I3S.java:24: G[: ́̕AGR[fBOMS932Ƀ}bvł܂
System.out.println( "surr:?𡈽𩸽𡗗" );
^
G[2
-encoding UTF-8 を指定することで正しくコンパイルされ、上記のようにして実行できます。
''の位置を変えてみました。やはりドットが問題のようです。
PS Z:\java\print04w> javac -encoding UTF-8 CodePageTestU8W8I3S.java PS Z:\java\print04w> java -D'file.encoding'=UTF-8 CodePageTestU8W8I3S os.name: Windows 10 os.version: 10.0 java.version: 1.8.0_212 java.vendor: AdoptOpenJDK sun.jnu.encoding: MS932 file.encoding: UTF-8 sun.stderr.encoding: cp65001 0208:東西南北 IBME:杦樰鉧銧 0213:囨艹辶鰙 surr:𠀋𡈽𩸽𡗗
キャプチャ画像も残しておきます。
typeの動作が65001の触れ込みとは異なり、MS932のままのような印象を受ける
Javaの出力をUTF-8にするとうまく表示されたことから、powershellの表示はUTF-8になっていて、Javaにはそれが伝わらずにいると考えると辻褄が合う。typeの結果と矛盾する。
しかし、昨日はなかなか辻褄の会う結果が出ず、今日になってうまく行くようになった。不安定な印象。
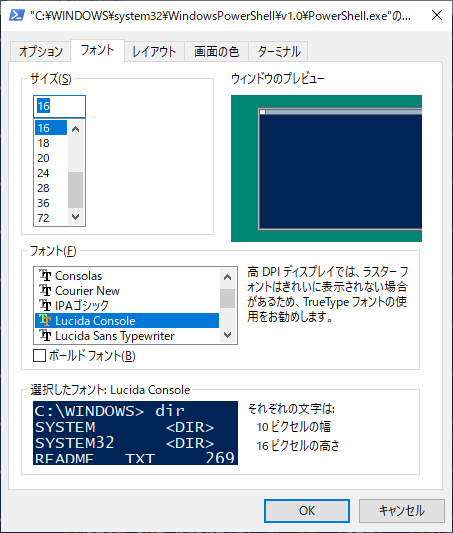
また、昨日はcpを65001にすると、文字フォントが Lucida console になってしまった。これには英数字のグリフが含まれずに日本語が表示されない事態になる。GUIでフォントを変更しても効果がなかった。cpが65001だと変更しても無視されるという情報もあった。今日はIPAゴシックで固定されている。昨日の最後、cp932の状態で変更したのが残っているのかもしれない。cpを替えるとフォントのリストも変化するのでなかなか厄介である。
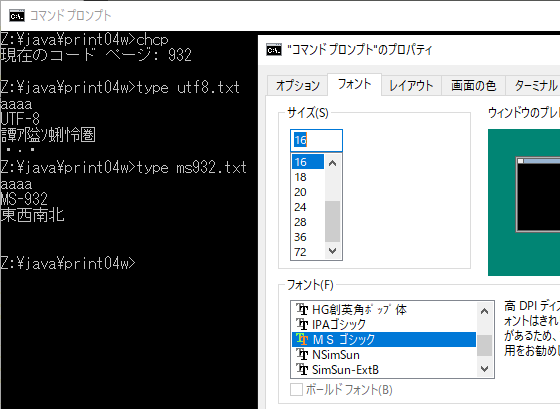
932では ms932.txt が正しく表示され utf8.txtは文字化け。フォントはMSゴシックが標準
もとよりJIS X0213 で追加された文字は期待できないが、IBM拡張も出ない。
65001では utf8.txt が正しく表示され ms932.txtは文字化け。フォントはMSゴシックのまま。
MSゴシックがそもそもMS932の範囲のグリフしか無いとも考えられる。
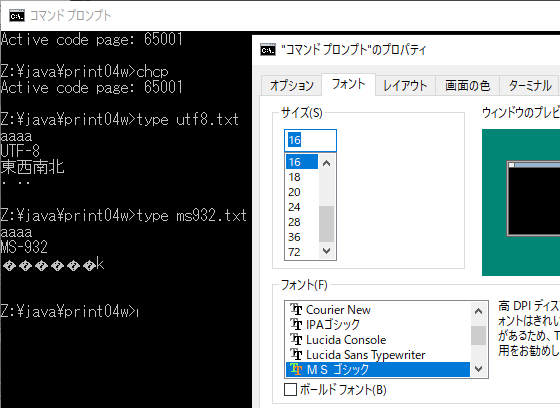
というわけで、IPAゴシックにしてみた。
https://docs.microsoft.com/en-us/windows/win32/intl/code-page-identifiers 932 shift_jis ANSI/OEM Japanese; Japanese (Shift-JIS) 1200 utf-16 Unicode UTF-16, little endian byte order (BMP of ISO 10646); available only to managed applications 1201 unicodeFFFE Unicode UTF-16, big endian byte order; available only to managed applications 12000 utf-32 Unicode UTF-32, little endian byte order; available only to managed applications 12001 utf-32BE Unicode UTF-32, big endian byte order; available only to managed applications 65000 utf-7 Unicode (UTF-7) 65001 utf-8 Unicode (UTF-8)
chcpはUTF-8対応と言っても西洋諸国の文字への対応に限るのかもしれません。
65001がUTF-8だといいますが、エラー出力は\00がたくさん入ってUTF-16ではないかと思われるフシがあります。
いずれにしても使えないので、これ以上時間を掛けるのはやめます。エディタさえ選択を誤らなければ、コンパイルまでは問題はありません。文字出力はGUIで済ませられます。あるいはファイルに書き出すのもよいでしょう。