mm2ptは mm to point の変換定数でmm単位の値に掛け算することでpointになるようにします。
float hbas = 20.0f; //左端の位置 float hwkm = 27.5f; //科目名の幅 float hwtn = 7f; //単位数の幅 float hptch = 45f/4; //学期などの幅 float vthtop = 41.0f; //ヘッダ行の上の位置 float vtdtop = 64.0f; //行データの上の位置 float vptch = 9.8f; //行データの各行の高さ float mm2pt = 72/25.4f;
テストデータ
ListとかMapで用意してみたが、説明が多くなるのでやめにして、単純に配列に用意した。
String[] kams = { "国語総合","現代社会","数学Ⅰ","数学A","化学基礎",
"生物基礎","体育","保健","音楽Ⅰ","コミュニケーⅠ",
"英語表現Ⅰ","家庭基礎","情報の科学" };
int[] tans = { 6,3,4,2,2,
2,2,1,1,2,4,
2,2,2 };
int[] tens = { 55,45,65,45,75,
45,55,55,60,45,
65,65,55 };
使い方としてはこんな感じ
for(int i=0; kams.length>i; i++){
y =....
x1=....
g2.drawString(kams[i], x1, y);
g2.drawString(String.ValuOf(tans[i]), x2, y);
g2.drawString(String.format("%3d",tens[i], x3, y);
}
均等割付と書ける分だけ書く機能
基本的な考え方
fmwmは文字を配置する場所の幅、ここに「国語総合」という文字列を配置する。まず現在のフォントでの印字幅を求めて差を求めremmに代入する。均等割付けをするときはremmを(文字数-1)でわったスペースを文字に挟む。中央揃えではremmの半分を前に置く。
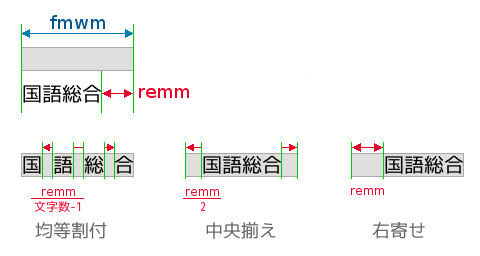
実際にはさらにfmwmに入りきらないときは文字列を一文字ずつ減らしてremmがプラスになったらそこまでを書く。どこまで書いたかをわかるようにして、残りを次の行に書くことができるようする。
均等割つけとともに、この書けるだけを書くという機能が重要な役目を果たす。
均等割付をするクラス AjustString
AjustStringというクラスを作ります。
コンストラクタ
AjustString(Graphics2D g2, String mojiretsu, float wakuhaba);文字列 mojiretsu を 枠幅 wakuhaba (単位はmm) に書くために用意をします 枠幅に書けるだけの文字列を用意し余白を計算し、書ききれない部分の先頭を記憶します 文字の大きさはGraphics2Dに設定されたフォントから計算します。AjustString(Graphics2D g2, String mojiretsu, float wakuhaba int kaishimoji);文字列 mojiretsu の 開始文字を指定します。他は開始文字指定のないものと同等です。
メソッド
drawKintou(float x, flaot y)枠幅に書ける分の文字列を g2の(x,y)を始点にした枠幅に、均等割付で書きます。drawCenter(float x, flaot y)枠幅に書ける分の文字列を g2の(x,y)を始点にした枠幅に、センタリングで書きます。drawRight(float x, flaot y)枠幅に書ける分の文字列を g2の(x,y)を始点にした枠幅に、右寄せで書きます。drawLeft(float x, flaot y)枠幅に書ける分の文字列を g2の(x,y)を始点にした枠幅に、左寄せで書きます。boolean hasNext()枠幅に文字列全部を書けない場合、true返します。int getNextPt()文字列全部を書けない場合に残った文字列の先頭が0から数えて何文字目かを返します。
使用例
"国語総合"という文字列を(20mm,80mm)を始点にして幅30mm,に均等割付けで収めるには次のようにします。
AjustString kp = new AjustString(g2, "国語総合", 30f-2f); kp.drawKintou(20f+1f,80f);
幅から2mmを減じて書く位置を1mm増やすことで枠線から両側に1mmの余白を置いています。
均等割付プログラム解説
文字を書くための幅がどれぐらい必要かは、Graphics2D g, String mojiretsuとして、
FontMetrics fm = g.getFontMetrics(); float widthinpt = fm.stringWidth(mojiretsu);
これで、float widthinpt にポイント単位で得ることができます。
プロポーショナルなフォントの場合に対応するかと期待したのですが、今のところそのような場面に出会ったことはありません。SerifもSansSerifもプロポーショナルではなくMonospacedと同じ等幅フォントになってしまうので、確認できていませんが、対応済みという事になります。
入りきらないときは文字列を一文字ずつ減らして必要な幅を求めなおし、指定された幅との差を覚えておきます。
drawKintou()の様なメソッドで入りきる様に短くなった文字列と指定された幅との差を使って文字を書いていきます。
サロゲートペアの扱い
面倒なのは、サロゲートペア対応です。Javaは内部的にUTF-16のユニコードを使用しています。ユニコードは当初世界の文字を16ビットで網羅できると考えていました。漢字を知っている国の人ならばすぐに無理と直感するところです。Javaもこれに合わせて文字は16ビットと設計されました。ユニコードはその後拡張され、16ビットで表現されない文字を補助文字と呼ぶようになりました。ユニコードの表現方法はいくつかありますが、Javaの採用するUTF-16は補助文字は特別な範囲の16ビット文字を2つ使用して表します。これをサロゲートペアと呼びます。Stringの中では2文字分で1文字を表しています。1文字減らすのに文字によっては2文字分減らすことが必要になるわけです。
拡張されたユニコードは全部で21ビットで表されます。8の倍数でないのはサロゲートペアを使って表現できる最大数を上限にすることに決めたからです。21ビットならintで表現できます。Javaではこれを Unicode コードポイントと呼びます。ユニコードでは Unicode スカラー値と呼んで U+897F U+2000B などと16進数で表します。UTF-16対応のメソッドに比べて使いにくいもののコードポイントとの換算は一応できるようになっています。
補助文字が必要になることはめったにないのですが対応しておくことは必要でしょう。「𠮷」という文字があります。U+20BB7です。土の下に口です。JISでは「吉」の字(U+5409)と同じ文字とみなされていますが、ユニコードでは区別されています。JISの範囲外であることからフォントが用意されていなくて使えないという環境もあるかもしれませんが、使われることは考えられます。
"東a西𠀋南ア北" という文字列を使ってJavaの文字列の扱いを掴んでおきます。このうち"𠀋"が補助文字で特別な配慮が必要です。"a", "ア" はShift_JISとは異なり、UTF-16では全て16ビットで他の文字と同じ扱いになります。
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| String内部のCharの配列 | 67 71 | 00 61 | 89 7f | d8 40 | dc 0b | 53 57 | ff 71 | 53 17 |
| 対応する文字 | 東 | a | 西 | 𠀋 | 南 | ア | 北 | |
| コードポイントによる番号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
サロゲートペアを含まない時は入門書で学ぶようにlength(),substring()を使えばよいのですが、サロゲートペアを含む文字列では間違った結果になります。
次の2つのメソッドを使って正しく書くことができます。文中のindexは文字列を構成する配列の添字を指します
- int codePointCount(int beginIndex, int endIndex)
- この String の指定されたテキスト範囲の Unicode コードポイントの数を返します。
- int offsetByCodePoints(int index, int codePointOffset)
- この String 内で、指定された index から codePointOffset コードポイント分だけオフセットされた位置のインデックスを返します。
いくつか例をあげます
文字数を求める
String str = "東a西𠀋南ア北"; System.out.println(str.length()); // → 8 (1つ多い) System.out.println(str.codePointCount( 0 , str.length() ); // → 7
先頭から5文字の部分列を取得
String str = "東a西𠀋南ア北"; System.out.println(str.substring(0,5)); // → 東a西𠀋 (4文字しかない) int index = str.offsetByCodePoints(0,5); System.out.println(str.substring(0,index)); // → 東a西𠀋南
一文字ずつ取り出す(サロゲートペアを含んでいると間違い)
String str = "東a西𠀋南ア北";
for (int i=0; str.length()>i ;i++){
System.out.println(i+"-"+(i+1)+" "+str.substring(i,i+1));
}
3-5で一文字なのに、3-4,4-5と分けると正しい字にならない
0-1 東 1-2 a 2-3 西 3-4 ? 4-5 ? 5-6 南 6-7 ア 7-8 北
一文字ずつ取り出す正しい方法
String str = "東a西𠀋南ア北";
int cdct = str.codePointCount(0, str.length());
for (int i=0; cdct>i; i++){
int idxbgn = str.offsetByCodePoints(0, i); //(index, codePointOffset)
int idxend = str.offsetByCodePoints(0, i+1);
System.out.println(idxbgn+"-"+idxend+" "+str.substring(idxbgn,idxend));
}
𠀋のところは3-5を取り出して正しく表示される
0-1 東 1-2 a 2-3 西 3-5 𠀋 5-6 南 6-7 ア 7-8 北
ソースコードの一部 (AjustString.java)
コンストラクタとテスト用のテスト用のmain()のみでテストします。動作確認用のSystem.out.println()が残っています。
AjustString.java コンストラクタとテスト用のmain()のみ
package print01;
import java.awt.Graphics2D;
import java.awt.Font;
import java.awt.FontMetrics;
import java.awt.image.BufferedImage;
public class AjustString {
String kp, nbf;
int cpct, idxbgn, newcpbgn;
float fmwm, remm;
float aidamm = 0f;
Graphics2D g;
FontMetrics fm;
float mm2pt = 72/25.4f;
float pt2mm = 25.4f/72;
public AjustString(Graphics2D g, String mojiretsu, float wakuhaba) {
this(g,mojiretsu,wakuhaba,0);
}
public AjustString(Graphics2D g, String mojiretsu, float wakuhaba, int kaishiichi) {
this.g = g;
kp = (mojiretsu!=null)? mojiretsu:""; //nullなら""
fmwm = (wakuhaba>=0)?wakuhaba:0; //負なら0
fm = g.getFontMetrics();
cpct = kp.codePointCount(0,kp.length()); //kpのcp数
if (0>kaishiichi) kaishiichi=0; //負なら0
if (cpct>kaishiichi){ //cpをindexに換算
idxbgn = kp.offsetByCodePoints(0,kaishiichi);
nbf = kp.substring(idxbgn);
}else{ //開始位置が文字列をはみ出していたら
idxbgn = kaishiichi-cpct+kp.length();
nbf = "";
}
System.out.println("cpct="+cpct+" /kaishiichi="+kaishiichi+" /idxbgn="+idxbgn+" /nbf="+nbf);//test
remm = fmwm - fm.stringWidth(nbf)*pt2mm; //あまりを計算
newcpbgn = kaishiichi + nbf.codePointCount(0, nbf.length()); //書いた後の次の文字を計算
System.out.println( "nbf="+nbf+" /remm="+remm +" /nbf.length()="+nbf.length()+" /newcpbgn="+newcpbgn);//test
while(0>remm && !nbf.isEmpty()) {
int newendidx = nbf.offsetByCodePoints(nbf.length(), -1); //一つ前のindexを求める
nbf = nbf.substring(0,newendidx);
remm = fmwm - fm.stringWidth(nbf)*pt2mm;
newcpbgn = kaishiichi + nbf.codePointCount(0, nbf.length());
System.out.println( "nbf="+nbf+" /remm="+remm +" /nbf.length()="+nbf.length()+" /newcpbgn="+newcpbgn);//test
}
}
public static void main( String[] args ) {
BufferedImage buffimg = new BufferedImage(400,300,BufferedImage.TYPE_INT_RGB);
Graphics2D g = buffimg.createGraphics();
g.setFont(new Font(Font.SERIF, Font.PLAIN, 10));
float wakuhaba = (args.length>0) ? Float.parseFloat(args[0]):10f;
int kaishiichi = (args.length>1) ? Integer.parseInt(args[1]):0;
String mojitachi="東a西𠀋南ア北";
System.out.println("文字列="+mojitachi+" /枠幅(mm)="+wakuhaba+" /開始番号(0-)="+kaishiichi);
AjustString as = new AjustString(g, mojitachi,wakuhaba,kaishiichi);
}
}
動作結果
実行時に引数を2つ入れます。枠幅と開始番号です。文字列は"東a西𠀋南ア北"固定です。
まず、27mmで0から
$ java print01.AjustString 27 0 文字列=東a西𠀋南ア北 /枠幅(mm)=27.0 /開始番号(0-)=0 cpct=7 /kaishiichi=0 /idxbgn=0 /nbf=東a西𠀋南ア北 nbf=東a西𠀋南ア北 /remm=5.833334 /nbf.length()=8 /newcpbgn=7
whileに入る前にremmが正の値になるので終わりです。nbf=が枠に入る文字列、remm=が余りの幅、newcpbgn=が書ききれない部分の先頭ですが、書ききれるので全体の0から数える文字数=6より1多い数になっています。
15mmに0からだと
$ java print01.AjustString 15 0 文字列=東a西𠀋南ア北 /枠幅(mm)=15.0 /開始番号(0-)=0 cpct=7 /kaishiichi=0 /idxbgn=0 /nbf=東a西𠀋南ア北 nbf=東a西𠀋南ア北 /remm=-6.166666 /nbf.length()=8 /newcpbgn=7 nbf=東a西𠀋南ア /remm=-2.6388893 /nbf.length()=7 /newcpbgn=6 nbf=東a西𠀋南 /remm=-0.875 /nbf.length()=6 /newcpbgn=5 nbf=東a西𠀋 /remm=2.6527777 /nbf.length()=5 /newcpbgn=4
"東a西𠀋"までにすると remmが初めて正になるのでそこで終わっています。newcpbgn=4は書ききれない部分の先頭ですが、0から数えると南が4になります。
1mmに0からだと
$ java print01.AjustString 1 0 文字列=東a西𠀋南ア北 /枠幅(mm)=1.0 /開始番号(0-)=0 cpct=7 /kaishiichi=0 /idxbgn=0 /nbf=東a西𠀋南ア北 nbf=東a西𠀋南ア北 /remm=-20.166666 /nbf.length()=8 /newcpbgn=7 nbf=東a西𠀋南ア /remm=-16.63889 /nbf.length()=7 /newcpbgn=6 nbf=東a西𠀋南 /remm=-14.875 /nbf.length()=6 /newcpbgn=5 nbf=東a西𠀋 /remm=-11.347222 /nbf.length()=5 /newcpbgn=4 nbf=東a西 /remm=-7.8194447 /nbf.length()=3 /newcpbgn=3 nbf=東a /remm=-4.2916665 /nbf.length()=2 /newcpbgn=2 nbf=東 /remm=-2.5277777 /nbf.length()=1 /newcpbgn=1 nbf= /remm=1.0 /nbf.length()=0 /newcpbgn=0
1文字も書けません。書かないので1mmがあまりになりますし、newcpbgn=0 つまり書ききれない部分の先頭は元の文字列の先頭です。
newcpbgnで見ると1文字ずつ減らしていることがわかります。nbf.length()の値からサロゲートペアを考慮しているのが見えます。
次の例は、"東a西𠀋"まで書いたので、"南"からの続きを書くという時のものです。先ほどのnewcpbgn=4の4を入れてコンストラクタを呼びます
$ java print01.AjustString 15 4 文字列=東a西𠀋南ア北 /枠幅(mm)=15.0 /開始番号(0-)=4 cpct=7 /kaishiichi=4 /idxbgn=5 /nbf=南ア北 nbf=南ア北 /remm=6.1805553 /nbf.length()=3 /newcpbgn=7
今度は"南ア北"と全部入ります。
AjustString.java ソースコードの残りの部分
drawKintou()はサロゲートペア対応のためとstringWidth()を使いながら1文字ずつ書く関係で面倒ですが、他は単純です。
AjustString.javaの残りのメソッド
public boolean hasNext(){
return cpct>newcpbgn;
}
public int getNextPt(){
int retval = -1;
if (cpct>newcpbgn) retval=newcpbgn;
return retval;
}
public float getLastRemm(){
return remm;
}
public void drawLeft(float hm, float vm) {
g.drawString(nbf,hm*mm2pt,vm*mm2pt);
}
public void drawRight(float hm, float vm) {
g.drawString(nbf,(hm+remm)*mm2pt,vm*mm2pt);
}
public void drawCenter(float hm, float vm) {
g.drawString(nbf,(hm+remm/2)*mm2pt,vm*mm2pt);
}
public void drawKintou(float hm, float vm) {
float hpp = 0;
int nbflen = nbf.length();
int nbfcplen = nbf.codePointCount(0,nbflen);
if (nbfcplen!=1){
aidamm = remm/(nbfcplen-1);
int i=0;
int nexti = 0;
int cpct = 0;
while (nbflen>i){
nexti = nbf.offsetByCodePoints(i,1);
g.drawString(nbf.substring(i,nexti),(hm+aidamm*cpct)*mm2pt+hpp,vm*mm2pt);
hpp = fm.stringWidth(nbf.substring(0,nexti)); //pt when 0?
i=nexti;
cpct++;
}
}else{
drawCenter( hm, vm);
}
}
通知表の文字部分を書く (Tsuuchi.java)
Tsuuchi.java
package print01;
import static java.awt.Font.*;
import java.awt.*;
import java.awt.print.*;
import java.awt.geom.Line2D;
import java.awt.geom.Rectangle2D;
import javax.print.attribute.HashPrintRequestAttributeSet;
import javax.print.attribute.HashPrintJobAttributeSet;
import javax.print.attribute.PrintRequestAttributeSet;
import javax.print.attribute.PrintJobAttributeSet;
import javax.print.attribute.standard.MediaSize;
import javax.print.attribute.standard.MediaSizeName;
import javax.print.attribute.standard.OrientationRequested;
import javax.print.attribute.standard.MediaPrintableArea;
import javax.print.attribute.standard.MediaTray;
import javax.print.attribute.Attribute;
public class Tsuuchi implements Printable {
String[] kams;
int[] tans, tens;
public Tsuuchi(String[] kams, int[] tans, int[] tens){
this.kams = kams;
this.tans = tans;
this.tens = tens;
}
@Override
public int print(Graphics g, PageFormat pf, int pageIndex) {
if (pageIndex != 0) return NO_SUCH_PAGE;
Graphics2D g2 = (Graphics2D)g;
float hbas = 20.0f; //左端の位置
float hwkm = 27.5f; //科目名の幅
float hwtn = 7f; //単位数の幅
float hptch = 45f/4; //学期などの幅
float vthtop = 41.0f; //ヘッダ行の上の位置
float vtdtop = 64.0f; //行データの上の位置
float vptch = 9.8f; //行データの各行の高さ
float mm2pt = 72/25.4f;
float pt2mm = 25.4f/72;
Font font10 = new Font("Serif", Font.PLAIN, 10);
g2.setFont(font10);
float padbtm = (vptch-g2.getFontMetrics().getHeight()*pt2mm)/2;
float vm,hm;
AjustString kp;
for (int k=0; kams.length>k; k++){
vm = vtdtop+vptch*(k+1)-padbtm;
kp = new AjustString(g2, kams[k] ,hwkm-2f);
kp.drawKintou(hbas+1f,vm);
kp = new AjustString(g2, String.valueOf(tans[k]), hwtn);//単位数
kp.drawCenter(hbas+hwkm,vm);
kp = new AjustString(g2, String.format("%3d",tens[k]), hptch);//評点1
hm = hbas+hwkm+hwtn;
kp.drawCenter(hm,vm);
}
return PAGE_EXISTS;
}
public static void main(String[] args) {
String[] kams = { "国語総合","現代社会","数学Ⅰ","数学A","化学基礎",
"生物基礎","体育","保健","音楽Ⅰ","コミュニケーⅠ",
"英語表現Ⅰ","家庭基礎","情報の科学" };
int[] tans = { 6,3,4,2,2,
2,2,1,1,2,4,
2,2,2 };
int[] tens = { 55,45,65,45,75,
45,55,55,60,45,
65,65,55 };
PrinterJob pj = PrinterJob.getPrinterJob();
PrintRequestAttributeSet reqset = new HashPrintRequestAttributeSet();
MediaSizeName medname = MediaSizeName.ISO_A4;
//MediaSizeName medname = MediaSizeName.JAPANESE_POSTCARD;
reqset.add(medname);
MediaSize medsize = MediaSize.getMediaSizeForName(medname);
float medwidth = medsize.getX(MediaPrintableArea.MM);
float medheight = medsize.getY(MediaPrintableArea.MM);
float topmm = 8.8f; //landscape前のTOP
float bottomm = 7.7f;
float leftmm = 6.6f;
float rightmm = 5.5f;
reqset.add(new MediaPrintableArea(
leftmm, topmm,
(medwidth - leftmm - rightmm),
(medheight - topmm - bottomm), MediaPrintableArea.MM));
//reqset.add(OrientationRequested.REVERSE_LANDSCAPE);
//reqset.add(OrientationRequested.LANDSCAPE);
reqset.add(OrientationRequested.PORTRAIT);
pj.setPrintable(new Tsuuchi(kams,tans,tens)); //printable instance
if (pj.printDialog( reqset )) {
boolean debug = true;
if(debug){
Attribute[] attrs = reqset.toArray(); //test
for(int n=0 ; attrs.length > n ; n++){ //test
System.out.println( attrs[n].getName()+":"+ attrs[n].toString()+";; ");
}
}
try { pj.print( reqset ); }
catch (PrinterException e) {
System.err.println(e);
}
}
}
}
実行結果
