Document Object Model はウェブページを構成する文書をjavascriptから操作するための仕組みです。W3Cで標準化の作業が続けられ、仕様が拡張されています。ブラウザの種類やバージョンごとに対応していたり、していなかったり、独自拡張もあったりとさまざまです。
2009年に互換性を調べて使えるメソッドやプロパティを厳選し、「授業で使ったプログラム」で紹介しているプログラムを書いていきました。
ここではそのメソッドやプロパティを一覧にして簡単な解説を加えます。それぞれの使用例は、今後別ページで書き足して行きます
第一項目の◎は使用頻度の高いものです。斜字体になっているものは、要素などのオブジェクトが格納された変数、文字列やそれが格納された変数に置き換えて使用します。文字列は "" や '' でくくります。裸の文字列は変数名と解釈されます。
| ◎ | document.getElementById(id) | idを使って要素を特定 |
| ○ | document.getElementsByTagName(tag) | タグ名で要素を抽出し配列で返す |
| ◎ | element.getElementsByTagName(tag) | getElementById()などで特定した要素(element)の内部から、タグ名で要素を抽出し配列で返す |
| document.getElementsByClassName(class) | クラス名で要素を抽出し配列で返す |
ここでelementはタグで囲まれたhtml内の要素のことです。
配列で返ってくるものの要素数は.lengthで調べます。[0]などの0から始まる数値で指定します。
私がDOMの勉強を始めた2009年にはインターネットエクスプローラ(IE)の独自拡張でFirefoxなど他のブラウザで使えない innerHTML と標準だけれどもIEでは使えない textContent という2つの手軽な方法がありました。いま(2018)ではどちらも使えるようです。innerHTMLの方はタグを含めて入力できてしまうので、外部からの入力を直接入れると危険です。
そこで、当時からこのどちらも使わず、.firstChild.nodeValue を使っていました。制約はあるし、ノードの知識が少し必要ですが、知っていると応用が効くのでいまでもおすすめな方法です。
| ◎ | element.firstChild.nodeValue | elementの文字列を取得する |
| ◎ | element.firstChild.nodeValue = value | elementの内容をvalueに換える。valueは文字列や数値、またはそれが入った変数 |
element内にすでに文字列が入っていることが必要です。スペースでも改行でも構いません。
詳細はテキストの取得と変更
id, class, src, href, style, onclick など、開始タグに attr="val" と書く場合、attrが属性名、valがその値です。
| ◎ | element.getAttribute(attr) | valが得られる |
| ◎ | element.attr | valが得られる。attrがclasのときはclassNameと書く |
| ◎ | element.setAttribute(attr,val) | attr=val となる。設定がなければ作られる。 |
| ◎ | element.attr = val | attr=val となる。設定がなければ作られる。 attrがclasのときはclassNameと書く |
2009年当時IEはgetAttribute()には対応しているものの、setAttribute()には対応していないというアンバランスなものでした。
今ならイベントの設定にはaddEventListener()も使えますが、ここに書かれた方法は、onclick, onmouseover などの属性設定の一つとして、統一的に把握できるところがメリットです。
詳細は属性の取得と変更
また、イベントハンドラも「属性」として設定することができます。これについてはイベントハンドラの取り付け
要素は作ってから追加します。最終的にdocumentに追加されて初めて表示されます。
parentはParentElement, childはChildElementです。
| ◎ | document.createElement(tag) | tagタグで囲まれる要素が作成される。document内にあるがまだ追加されていない。 |
| ◎ | parent.appendChild(element) | parentは親になる要素(getElement...などで得る)。 elementは子になる要素。親にすでに子があるときは最後に追加される。 |
| ◎ | parent.insertBefore(element, child) | parentが親要素で、childはその子要素としてすでにある要素。 このchildの前に、elementが子要素として追加される。 |
| ○ | parent.removeChild(child) | childを削除する。 |
| ◎ | document.createTextNode(string) | stringは文字列または、それが入った変数。 要素内に文字列を入れるときには、テキストノードにしてからappendChild必要がある。 逆に要素からテキストを取り出すときには、要素から子であるテキストノードを取得して そこからテキストを得る必要がある。これが、.firstChild.nodeValue である。 |
| ◎ | element.parentNode | element要素の親要素。 |
| ◎ | parent.firstChild | parent要素の最初の子要素(またはテキストノード)。 |
| ◎ | parent.lastChild | parent要素の最後の子要素(またはテキストノード)。 |
| element.nextSibling element.previousSibling |
element要素の次の要素(またはテキストノード)。親子関係でなく兄弟を探す。 改行だけの部分をテキストノードとするか否かがブラウザによるので、注意。 |
用語について気をつけたつもりですが、ノードと要素(エレメント)が混乱したかもしれません。しかし、ウェブページ作成に当たってはこの程度で十分と思います。getElement...のelementはhtmlを構成するh1,h2,pなどの要素のことを言います。DOMでは要素はエレメントノードになります。要素の中の文字列はテキストノードと呼ばれます。
ウェブ標準に関わる用語は変化していきます。たとえば、2009年に学んだときには「属性ノード」という言葉がありました。エレメントノードやテキストノードとは異質で、ノードになっていないと感じていましたが、今回調べると属性ノードという呼び方は廃止になったようです。
nodeTypeというプロパティはノードタイプを数値で返しますが、その一覧が下記です(使わないだろうというのは略しました)。空席の値である2がATTRIBUTE_NODEでした。
| 定数 | 値 | 説明 |
|---|---|---|
| Node.ELEMENT_NODE | 1 | <h1>や<p>などの要素 |
| Node.TEXT_NODE | 3 | 要素内のテキスト(タグ間の改行もテキストノードとされる場合もある) |
| Node.COMMENT_NODE | 8 | コメントノード |
| Node.DOCUMENT_NODE | 9 | Documentはhtmlの親. |
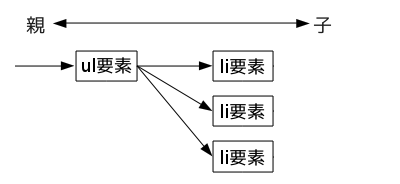
ノードという言葉は、ツリー構造をしている集合の結節点です。html文書もhtml要素の中にhead,bodyの2つの要素があり、bodyの中にはh1,h2,p要素などがあって、ul要素があれば、さらにその中にli要素がいくつかあるというように枝分かれをしているので、ツリー構造と見ることができます。h1,h2,pなどの要素が、ツリー構造のノードに当たっているわけです。
問題はテキストの位置づけです。テキストがh1,h2,pなどの要素に入っているだけならば、テキストノードと言わずに、単にノードの内容とか値とかの位置づけでよかったのですが、 テキストの途中に他のノードが入ることが起こりえます。たとえば b, i, span などの昔流に言えばインラインタグがある場合です。
こんな場合です。
<li>aaaaaa<span>bbbbbb</span>cccccc</li>
これをどのように解釈するかいろいろな発想があるかもしれませんが、DOMではaaaaaaとccccccがテキストノードという暗黙の枠に入ってspan要素のノードと並んでいると考えたわけです。
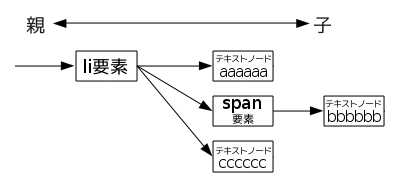
テキストノードの中のテキストをノードの「値」といいます。エレメントノードには値がありません。